Le processus général
Manypage est utilisé au sein d'une chaîne de production de site web.
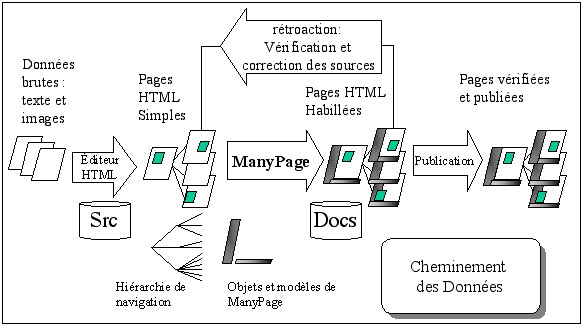
D'abord, l'équipe éditoriale collecte de l'information et la présente sous la forme de pages HTML simples. Elle pense par ailleurs à la hiérarchie de ces informations pour établir l'arbre de la navigation. A ce sujet, il est important de noter que la hiérarchie de navigation peut être différente de la manière dont seront rangés les pages dans une arborescence de répertoires sur le serveur. L'arbre de navigation correspond à la manière dont le websurfeur perçoit l'organisation du site et accède à une information. L'organisation des répertoires coïncide plus souvent avec la manière dont l'équipe éditoriale (et à travers elle l'organisme ou la compagnie) sont organisés. Il est parfois difficile, mais pourtant essentiel de faire comprendre aux personnes d'une organisation (les commanditaires d'un site) que la hiérarchie visible d'un site web, ne doit pas systématiquement refléter la hiérarchie interne de l'organisation.
Pour compléter ces données, les équipes graphiques et techniques ont préparé des menus et des éléments graphiques et ont décrit l'organisation de ces éléments sous la forme de modèles et de fichiers d'"objets HTML". Ces éléments qui vont être rajoutés aux pages sources représentent des outils importants pour aider les websurfeurs à utiliser votre site. C'est pourquoi nous vous proposons quelques exemples de ce que vous devriez mettre dans vos habillages.
Toutes ces données (pages HTML simples, images, fichiers
multimédias, description des arbres de navigation dans les fichiers .link,
description des modèles dans les fichiers .dress,
et description des objets HTML dans les fichiers .obj) sont
placées en ordre dans un répertoire (ou ses sous repertoires)
que nous nommons par habitude 'Src' (de 'Source', car il
contient tout ce qui est nécessaire à la construction du site
web).
A ce moment, ManyPage peut être lancé sur une ou plusieurs pages HTML, un répertoire ou une arborescence de répertoire, ou même l'ensemble du site web. Toutes les pages produites (et les documents multimédias joints) sont placés dans un second répertoire appelé 'Docs' (d'après le nom historique du répertoire par défaut du serveur httpd du NCSA). Il est alors possible d'effectuer un contrôle du résultats ainsi que les corrections adéquates, dans une "boucles de rétroaction").
C'est simplement quand tout est correct que les pages HTML habillées sont basculées vers le serveur web public, pour publication.
Il est conseillé de gérer la production du site (répertoires Src et Docs) sur une machine différente de la machine de publication (serveur web). Pour les individus, il est ainsi facilement possible de gérer toute la production de chez soi hors connexion, et de télécharger ensuite les pages habillées chez votre hébergeur.
Deux arbres différents : Imaginez une entreprise avec 4 départements principaux, mais dont uniquement deux d'entre eux soient en contact direct avec le public (vente de produits par exemple). Les quatre départements devraient pouvoir mettre de l'information dans un répertoire placé à la racine du site web. Cependant, de la page d'accueil (la fameuse 'home page'), seuls les deux premiers départements devraient être accessibles en un clic. Il pourrait alors y avoir un petit lien présentant les "autre services" permettant un accès aux services des deux autres départements par exemple. Ainsi ici, l'arbre de navigation (la hiérarchie des liens) est bien différent de la hiérarchie de l'organisation.